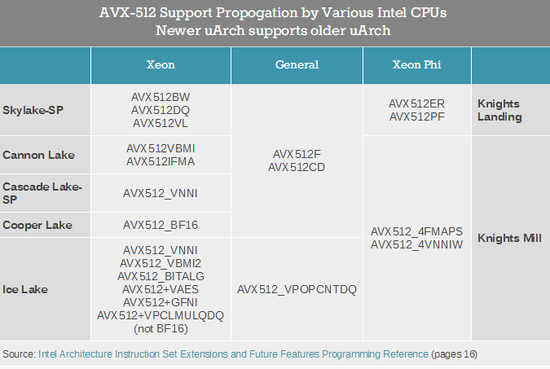
Intel近日发布了第二代可扩展至强处理器,代号为Cascade Lake,工艺还是14nm,架构还是Skylake-SP,而接下来在明年,Intel还将再拿出一代14nm服务器平台,代号为Cooper Lake,而且很可能更换接口和主板,再往后才轮到10nm Ice Lake。
Cascade Lake在机器学习、人工智能方面做了显著增强,Cooper Lake则会继续改进。根据Intel发布的最新版开发者文档,Cooper Lake会引入新的AVX512_BF16适量神经网络指令,也就是支持bfloat16(BF16)格式。
bfloat16(BF16)浮点格式介于标准化的半精度FP16、单精度FP32之间,指数位和FP32一样而多于FP16,但是小数位比FP16更少。
它能让开发者在16位空间内通过降低精度来获取更大的数值空间,在内存中存放更多数据,减少数据进出空间的时间,还能降低电路复杂度,最终带来计算速度的提升。
这种格式已经成为深度学习事实上的标准,Google TPU、Intel未来的FPGA及其Nervan神经网络处理器都会支持,Xeon至强家族支持也在情理之中。
Cooper Lake支持的AVX512-BF16指令包括VCVTNE2PS2BF16、VCVTNEPS2BF16、VDPBF16PS,而且都有128位、256位、512位三种模式,因此开发者可以根据需要选择九种不同版本。
不过奇怪的是,Intel每次公布新指令的时候,都会确认支持的首个架构以及此后支持的架构,比如最初的AVX指令集,支持的架构就标注为“Sandy Bridge and later”。
但这次,AVX512-BF16指令的支持架构却只写着“Future Cooper Lake”,并没有看到惯例的“and later”。
这似乎意味着,只有14nm Cooper Lake才会支持AVX512-BF16,而接下来的10nm Ice Lake反而会砍掉。
Intel对此回应称:“目前,Cooper Lake会为机器学习加速(DLBoost)加入Bfloat16指令。除此之外在路线图内没有可分享的。”
版权申明:本站文章均来自网络转载,本站无法鉴别所上传图片或文字的知识版权,如果侵犯,请及时通知我们,本网站将在第一时间及时删除。
|